Hybrid AI
Allowing companies to leverage LLMs without compromising their data, March 2025

Gaining insights from technical documents
The invention of the transformer architecture in 2017, making large language models (LLM) like ChatGPT possible, opened up a world of possibilities. Trained on a large corpus of documents, LLMs embody a compressed representation of humanity’s knowledge. Humans and machines can interact with LLMs by having a conversation with them in human language.
Rapidly, a technique known as Retrieval-Augmented Generation (RAG) emerged, allowing a user to ask specific questions about a body of documents the LLM has never seen before, leveraging its ability to understand human language and compile information. It became easy for anyone to retrieve information that may be spread across thousands of pages of confidential documents.

Reliability vs. confidentiality
LLMs require clusters of supercomputers to run them, which makes it impossible for most companies to run them on their own IT infrastructure. A few organizations like OpenAI run them and make them available to other companies through a paid API, so they can implement their own RAG solution without having to deploy costly infrastructure.
Today, these APIs are already affordable for most companies, making this setup look ideal at the first glance. Profitable RAG solutions can be implemented using them. But what if confidential data leak through these AI providers? Even if they have the best intentions, a security breach may always happen.
To keep their confidential data inside their limited private IT infrastructure, organizations could internally deploy and run small language models (SLM) instead, e.g. Llama. These smaller models however are often less reliable. They are more likely to generate wrong answers and make up facts on challenging tasks. As they have been trained on less knowledge, they are less likely to give interesting insights in response to prompts like “How would you go about recycling this?” given a technical specification of the product.

What if we could combine the performance of large language models with the confidentiality of smaller ones?

Anatomy of a confidential document
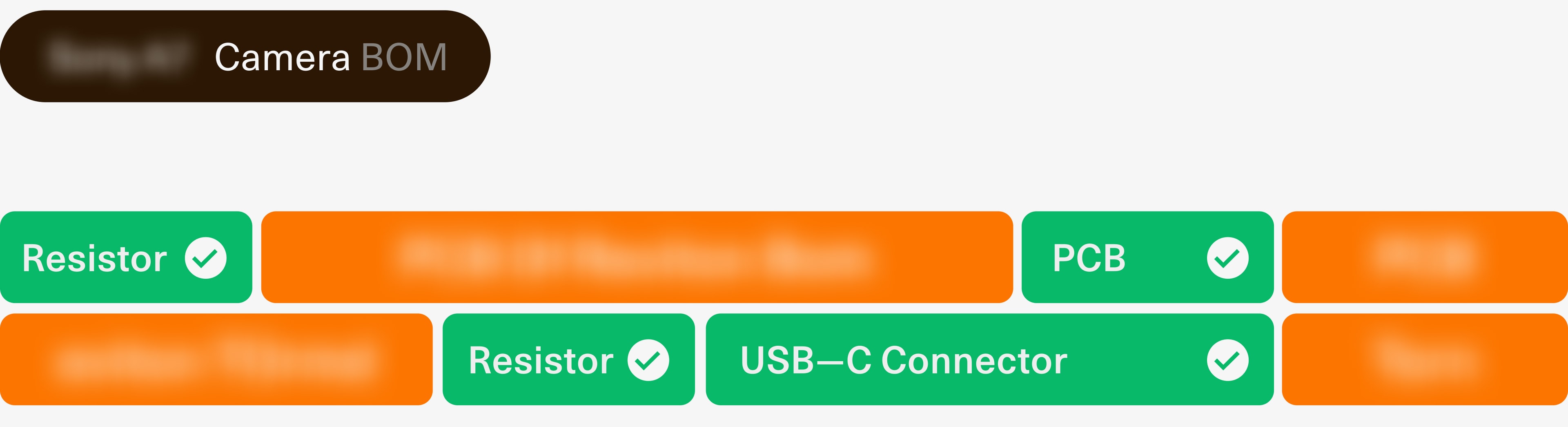
Solving this puzzle starts with acknowledging the fact that confidential documents do not exclusively contain confidential data. Take, for example, a camera that your business is developing. The entire bill of materials of the camera is confidential, but the fact that it contains a printed circuit board and a certain amount of resistors is not. The code name of the camera may be confidential but the fact that you are developing a camera may not be.
Realizing this allows one to design an application that leverages both small and large language models affordably, while keeping confidential data private.
Leveraging both small and large models in one application
An application built with privacy in mind could start with using small local AI models, running on private infrastructure, to break down documents into bits of data that are either highly sensitive, non-sensitive or sensitive only if provided together with other pieces of information.
The non-sensitive data can then be sent to a remote, powerful LLM to gain more advanced insights.
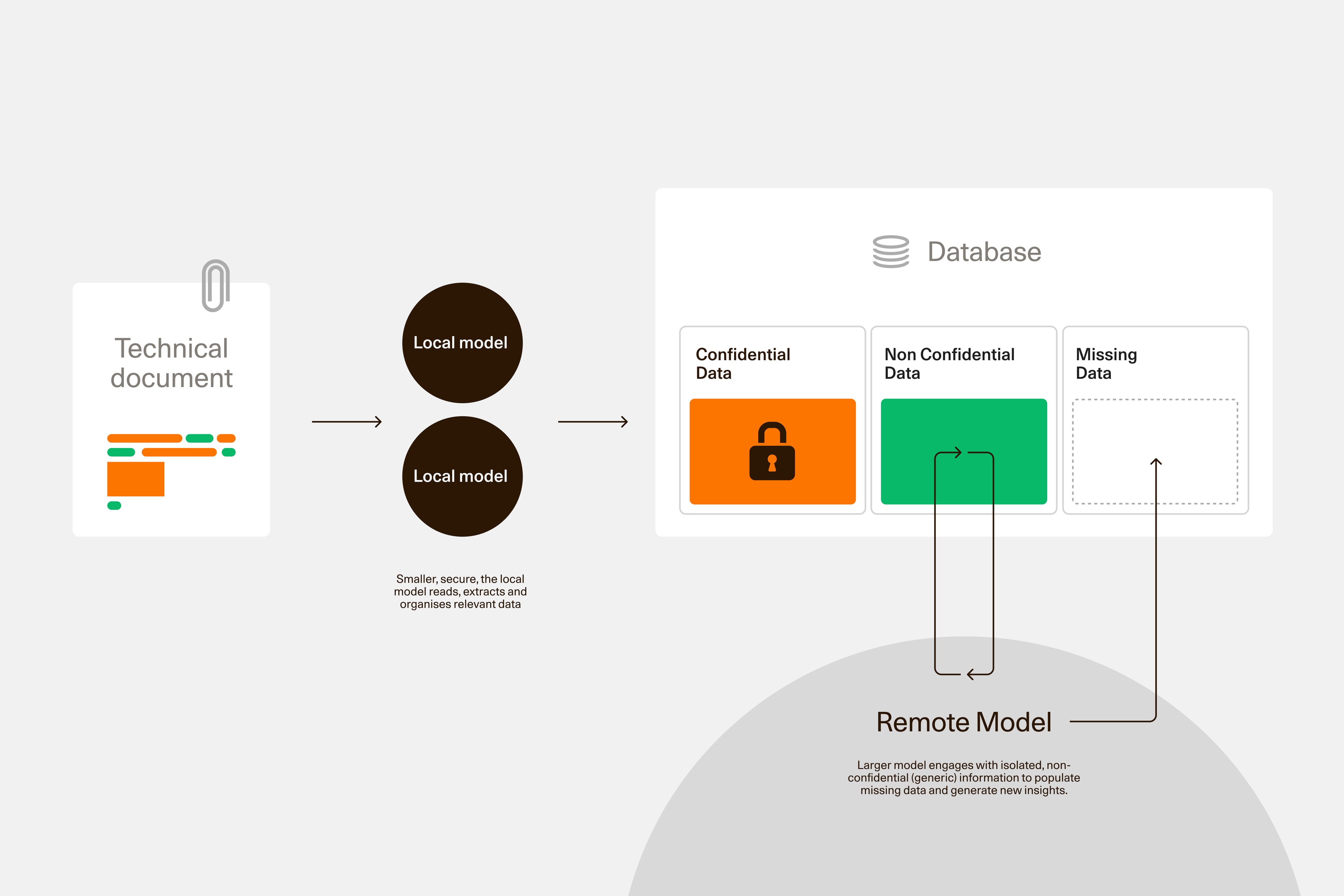
This technique is starting to emerge in the industry and is known under several names, e.g. Cascade Inference or Hybrid Remote/Local AI.
Example implementation
A typical back-end software stack for achieving this could leverage the LangChain and transformers libraries for querying local and remote AI models. The following Python example illustrates this. It can run on your laptop, leveraging the power of a remote large language model, while making sure the confidential document never leaves your computer.
import transformers
from langchain_core.messages import HumanMessage
from langchain_huggingface import HuggingFacePipeline
from langchain_openai import ChatOpenAI
from pydantic import BaseModel
OPENAI_API_KEY = "sk-proj-..."
HUGGINGFACE_TOKEN = "hf_..."
CONFIDENTIAL_DOCUMENT = """
Camera4242: Technical Specification
1. Introduction
Camera4242 is a camera module that can be used in a variety of applications,
including security cameras, drones, and IoT devices. It is designed to be easy
to integrate into existing systems and to provide high-quality images in a
variety of lighting conditions.
2. Features
- High-resolution sensor
- Wide dynamic range
- Low-light performance
- Power-efficient
3. Main electronic components
The Camera4242 module consists of the following electronic components:
- Image sensor
- Processor
- Memory
- Power management unit
- Communication interface
"""
def _main():
# Use a local small language model to extract non-confidential information
# from the confidential document.
slm = _create_slm()
confidential_messages = [
HumanMessage(
content=[
{"type": "text", "text": CONFIDENTIAL_DOCUMENT},
{
"type": "text",
"text": """
What are the main electronic components of the system
previously described? Only their names and nothing else.
""",
},
],
),
]
non_confidential_electronic_components = slm.invoke(
_to_slm_prompt(confidential_messages)
)
# Typical response:
# 1. Image sensor
# 2. Processor
# 3. Memory
# 4. Power management unit
# 5. Communication interface
print(non_confidential_electronic_components)
# Use a remote large language model to gain insights from the extracted
# non-confidential information.
llm = _create_llm()
non_confidential_messages = [
HumanMessage(
content=[
{
"type": "text",
"text": f"""
Consider an electronic system with the following main
components:
{non_confidential_electronic_components}
Which five raw materials are most likely to be found in
such a system?
""",
},
],
),
]
class RawMaterials(BaseModel):
raw_materials: list[str]
llm = llm.with_structured_output(RawMaterials)
non_confidential_raw_materials = llm.invoke(non_confidential_messages)
# Typical response:
# raw_materials=['Silicon', 'Copper', 'Aluminum', 'Gold', 'Tin']
print(non_confidential_raw_materials)
def _create_slm():
# See https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
model_name = "meta-llama/Llama-3.2-3B-Instruct"
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_name, token=HUGGINGFACE_TOKEN
)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>"),
]
model = transformers.AutoModelForCausalLM.from_pretrained(
model_name,
token=HUGGINGFACE_TOKEN,
trust_remote_code=True,
device_map="auto",
)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=200,
return_full_text=False,
eos_token_id=terminators,
)
return HuggingFacePipeline(pipeline=pipeline)
def _to_slm_prompt(messages):
# See https://www.llama.com/docs/model-cards-and-prompt-formats/llama3_1/
result = "<|begin_of_text|>\n"
for message in messages:
result += "<|start_header_id|>user<|end_header_id|>\n"
for content_item in message.content:
result += content_item["text"] + "\n"
result += "<|eot_id|>\n"
result += "<|start_header_id|>assistant<|end_header_id|>\n"
return result
def _create_llm():
return ChatOpenAI(
model="gpt-4o-mini-2024-07-18",
openai_api_key=OPENAI_API_KEY,
)
if __name__ == "__main__":
_main()
Challenges
A. Application is not document-agnostic
As you can see in the example, the application needs to know what kind of documents will be processed and what kind of information they contain. It needs some prior knowledge about the degree of confidentiality of each expected type of information. Implementing a RAG application that can process a wide range of document types will be challenging.
B. Large documents
SLMs work less reliably on large documents. The application will probably need to break these documents down into chunks and index these chunks by meaning. It will probably involve:
C. Tabular documents
Feeding an Excel-sheet to a language model in order to extract data is challenging. While converting the table to text, information gets lost, for example color and font weight, which readers are heavily relying on in order to spot which rows and columns represent a header and which ones represent values. A full solution will probably involve:
a local embedding model,
a table-to-text library like openpyxl, unstructured.io or LlamaParse,
letting the SLM generate code for retrieving data rather than directly returning the answer.
It may also be necessary to run larger SLMs for better results, while leveraging quantization in order to still be able to run the model on affordable hardware. Applied to the previous example:
model_name = "meta-llama/Llama-3.1-70B-Instruct"
model = transformers.AutoModelForCausalLM.from_pretrained(
model_name,
token=HUGGINGFACE_TOKEN,
model_kwargs={
"quantization_config": {"load_in_4bit": True},
"low_cpu_mem_usage": True,
},
trust_remote_code=True,
device_map="auto",
)
It is also possible, although often somewhat difficult, to retrieve the probability of each token output by the model, known as logprob. A recent approach consists of attempting to detect uncertainties or hallucinations using this value.
D. Documents containing images
SLMs that can reliably answer questions on images are still rare, to say the least. Llama 3.2 Vision for example isn’t available in the European Union as we are writing this. A full solution will probably require a local object detection model like facebook/detr-resnet or google/owlv2.
E. Different prompt formats
As one can see in the previous example, the prompt format, i.e. the format taken as input by a language model, varies from model to model and it may be interesting to switch to a framework that abstracts these details away, so that one can more easily implement an application interacting with various models, e.g. LlamaIndex, Ollama or LMQL.

Looking ahead
More such hybrid AI solutions will come to light as they bring the following advantages:
Confidentiality
Keeping what is not meant to be disclosed safe and ensuring compliance.
Predictability
More predictability, by sending less requests to external AI providers whose response time is uncertain.
Control
More control over scaling, by handling a bigger part of the AI tasks on one’s own IT infrastructure.
Savings
Cost efficiency and energy saving, by having a smaller average model size per request.
A recent emerging trend consists of fine-tuning (i.e. post-training) many domain-specific SLMs by distilling an LLM’s knowledge. In other words by using an LLM to train many SLMs. You can then run these SLMs on your own IT infrastructure, even with a limited amount of GPUs by using novel techniques like hotswapping LoRA adapters.
AI researchers, semiconductor companies and open-source software projects are bringing optimizations at a high pace currently, so that the barrier of fine-tuning and running many SLMs will rapidly decrease.
Project Team
Aurélien Lourot Research and Code Development Text Lucas Teixeira Visuals